
กูเกิลโชว์ USM โมเดลแยกแยะเสียงพูดที่รองรับมากกว่า 300 ภาษา มีภาษายาวีด้วย – SMS Marketing ราคาถูกที่สุด
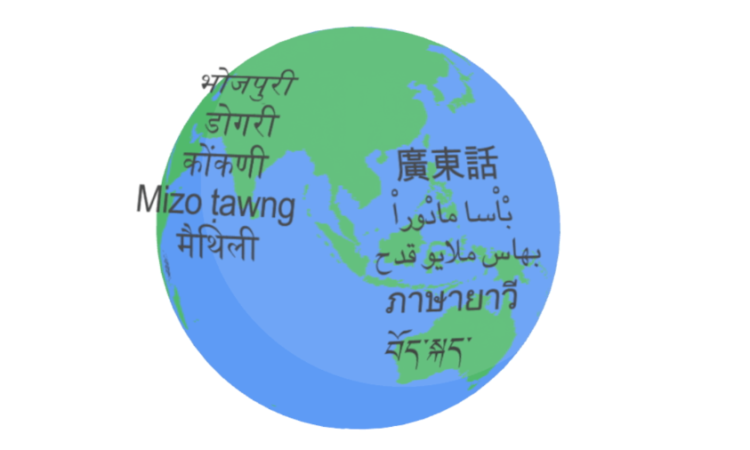
ทีมวิจัย Google Research เผยแพร่ข้อมูลของโมเดลแยกแยะเสียงพูดตัวใหม่ชื่อ Universal Speech Model (USM) ที่รองรับภาษามากกว่า 300 ภาษา ซึ่งครอบคลุมถึงภาษาที่อาจไม่ได้มีผู้ใช้งานเยอะนัก (จากภาพของกูเกิลจะเห็นคำว่า “ภาษายาวี” อยู่ด้วย)
โมเดล USM เป็นก้าวแรกสู่เป้าหมาย โมเดลเดียวรองรับ 1,000 ภาษา (1,000 Languages Intitiative) ที่กูเกิลเคยประกาศไว้ช่วงปลายปี 2022 โดยตอนนี้ USM ถูกนำไปใช้แล้วกับ YouTube ในการฟังเสียงจากวิดีโอแล้วสร้างเป็นซับไตเติลในภาษาต่างๆ
USM เลือกใช้แนวทาง self-supervised learning เรียนรู้จากการฟังเสียงพูดในภาษาต่างๆ โดยไม่จำเป็นต้องมีป้ายกำกับ (labeled) ซึ่งมีข้อจำกัดเรื่องปริมาณข้อมูลตัวอย่างเสียงที่มีป้ายกำกับ โดยเฉพาะภาษาที่มีผู้ใช้น้อย ในอีกทาง โมเดลจำเป็นต้องใช้ทรัพยากรประมวลผลให้มีประสิทธิภาพ เพราะต้องขยายจำนวนภาษาที่รองรับให้มากขึ้นเรื่อยๆ ด้วย
เทคนิคที่ USM ใช้งานคือ self-supervised learning with fine-tuning เพิ่มขั้นตอนการปรับแต่ง เพื่อให้ประสิทธิภาพของโมเดลออกมาดีขึ้น กระบวนการเทรนแบ่งเป็น 3 ขั้นตอนคือ
self-supervised learning จากเสียงพูด ใช้อัลกอริทึม BERT-based Speech pre-Training
with Random-projection Quantizer (BEST-RQ) ปี 2022 ที่อิงจากอัลกอริทึม BERT ของกูเกิลเมื่อปี 2018 ขั้นตอนนี้กินพลังประมวลผลราว 80% ของทั้งกระบวนการ
multi-objective supervised pre-training เพิ่มข้อมูลประเภทข้อความ (text data) ให้โมเดลมีความรู้เพิ่มขึ้น กูเกิลบอกว่าขั้นที่สองนี่จะทำหรือไม่ก็ได้ (optional) แต่ทำแล้วได้ผลลัพธ์ที่ดีขึ้น
fine-tune ปรับแต่งงานบางส่วนโดยใช้ข้อมูล supervised data อีกเล็กน้อย
ผลที่ได้คือโมเดล USM สามารถทำคะแนนผ่านชุดทดสอบ YouTube Captions ได้ดีกว่าโมเดลอื่น เช่น Whisper-v2 ที่เทรนด้วย labeled data โดยใช้ข้อมูลการเทรนน้อยกว่า และมีอัตราการผิดพลาดน้อยกว่า
กูเกิลบอกว่าสถาปัตยกรรมของ USM น่าจะถูกนำมาใช้เป็นพื้นฐานของโมเดลรุ่นถัดๆ ไปที่จะสามารถพิชิตเป้าหมายแยกแยะ 1,000 ภาษาได้สำเร็จ
ที่มา – Google AI Blog



{kind=link}